Abstract
Agentic large language model systems have demonstrated strong capabilities, but their reliance on language as the universal interface fundamentally limits their applicability to scientific problems with structured, non-linguistic inputs. Eywa addresses this gap by augmenting domain-specific foundation models with a language-model-based reasoning interface, enabling LLMs to guide specialized inference over heterogeneous scientific modalities.
The framework supports three levels of integration: EywaAgent as a drop-in replacement for a single-agent pipeline, EywaMAS as a plug-and-play extension of multi-agent systems, and EywaOrchestra as a planner that dynamically coordinates traditional agents and Eywa agents across tasks.
Across physical, life, and social science tasks, Eywa improves the quality-cost trade-off by combining generalized reasoning with specialized acting, reducing the language overhead of scientific problem solving while improving overall utility.
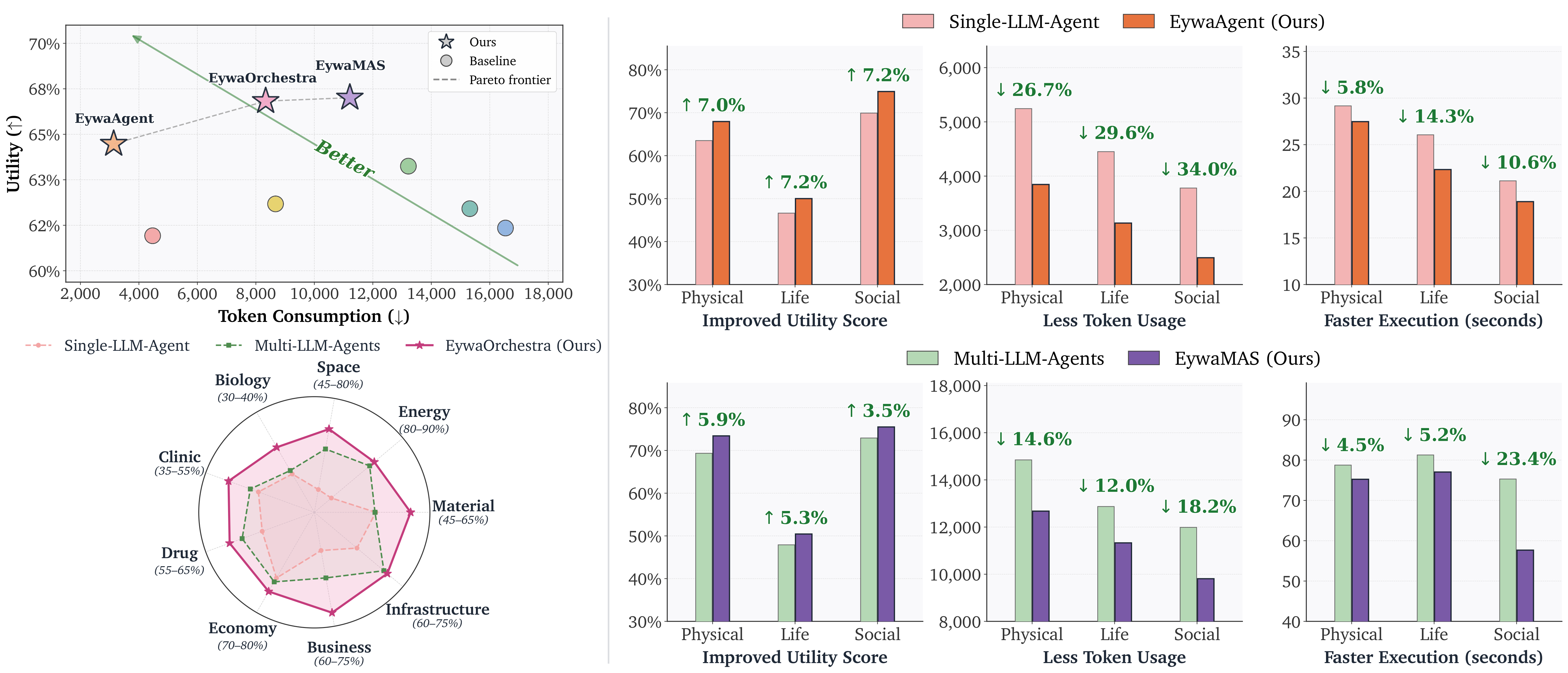
Project snapshot. Eywa improves the utility-cost frontier across physical, life, and social science tasks. The left side shows the overall Pareto trade-off, and the right-side panels show consistent gains in utility, token efficiency, and execution time across domains.
Eywa at a Glance
Eywa starts from FM-LLM "Tsaheylu" interface, then scales into multi-agent systems and adaptive orchestration.
Framework overview. The Pandora analogy introduces the three-step progression: a reasoning-augmented specialist, a plug-and-play heterogeneous MAS, and a conductor that orchestrates experts dynamically.
Why LLM-only reasoning is not enough
Scientific tasks often depend on structured data like time series and tables. A pure language agent has to serialize those inputs into text, reason over them token by token, and hope that the language interface preserves the task-relevant signal. The paper's core argument is that this creates an information bottleneck.
- Problem: the FM may not natively understand natural language, while the LLM lacks the specialist inductive bias.
- Tsaheylu interface: a query compiler turns task state into a structured invocation, and a response adapter turns FM output into planner-consumable context.
- Why tokens drop: modality-specific computation happens inside the specialist, so the LLM no longer spends long token traces simulating the prediction itself.
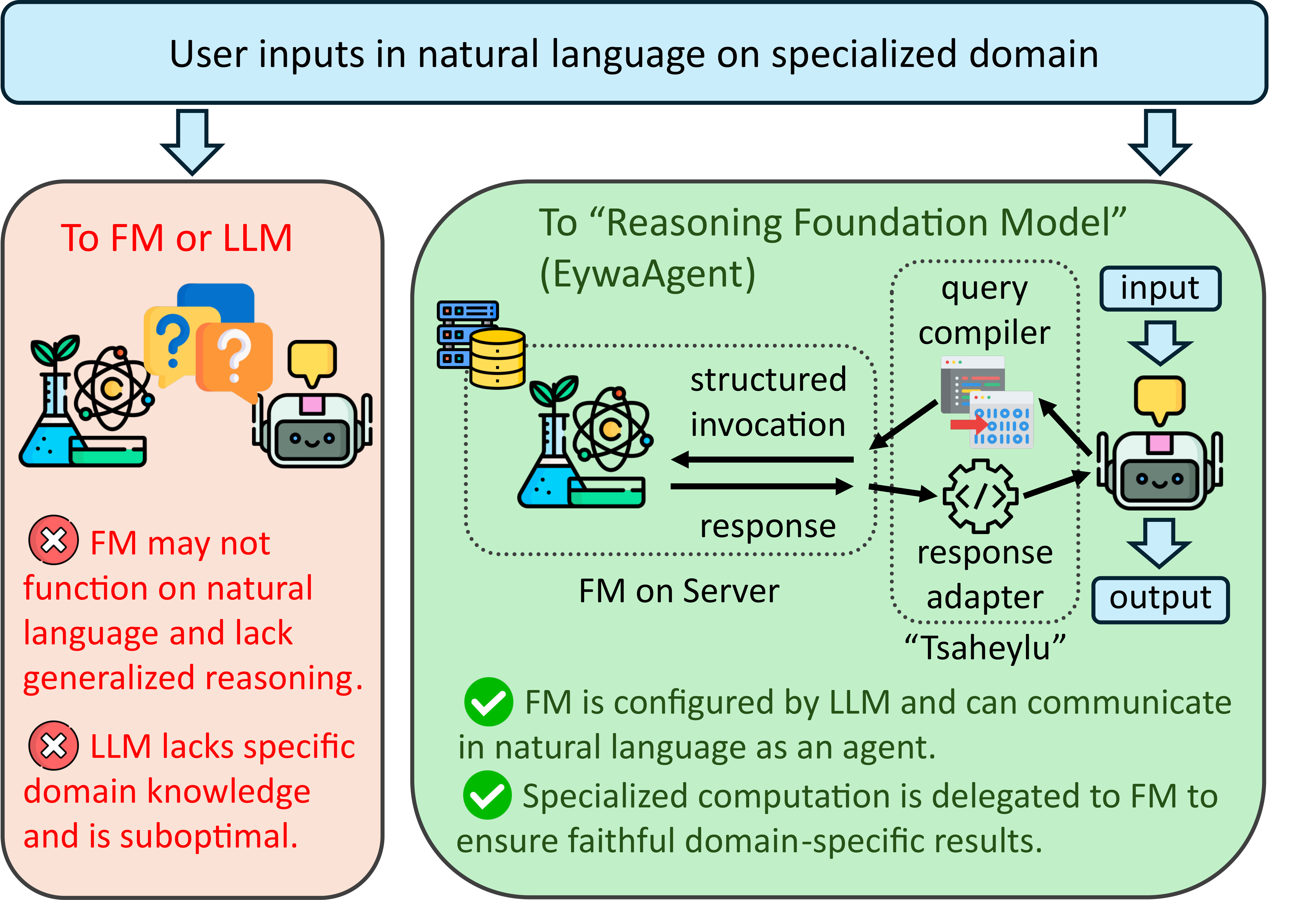
EywaAgent. The LLM parses the task, configures the specialist through Tsaheylu, delegates the core domain computation, then checks and realizes the final response in the required output format.
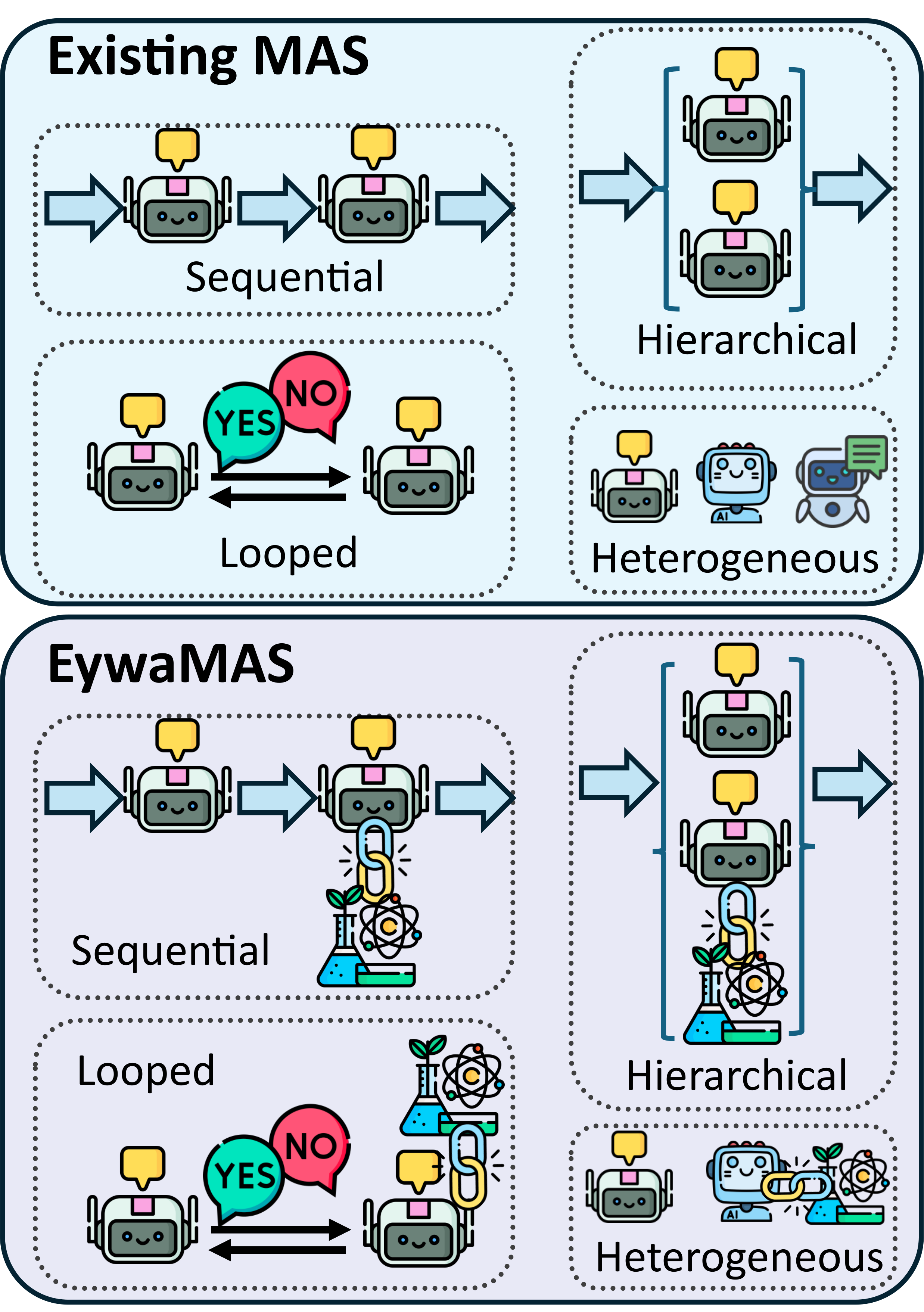
EywaMAS. Sequential, looped, hierarchical, and heterogeneous agent systems can all be upgraded by replacing selected language-only workers with EywaAgents.
How collaboration scales beyond one specialist
EywaMAS preserves the topology of an existing multi-agent system while replacing selected workers with specialist-backed agents. EywaOrchestra goes one step further and asks which configuration should be used for this task at all.
- Plug-and-play replacement: a planner, summarizer, or worker can stay in place while only the task-relevant workers become EywaAgents.
- Heterogeneous topologies: the framework supports sequential, looped, hierarchical, and mixed-agent collaboration rather than one fixed structure.
- Planner necessity: not every domain benefits equally from heavy multi-agent computation, so EywaOrchestra chooses model mix and topology based on the sample.
EywaBench Covers Real Scientific Structure
EywaBench is built to test heterogeneous scientific reasoning across domains, modalities, and task sources instead of flattening everything into one generic QA setting.
Released EywaBench-V1 tasks
The current split is a representative slice sampled from a larger, fully extensible benchmark construction pipeline.
Scientific sub-domains
Material, energy, space, biology, clinic, drug, economy, business, and infrastructure are all populated.
Domain-modality cells
All 27 combinations of sub-domain and modality are covered, avoiding the usual domain-collapse problem.
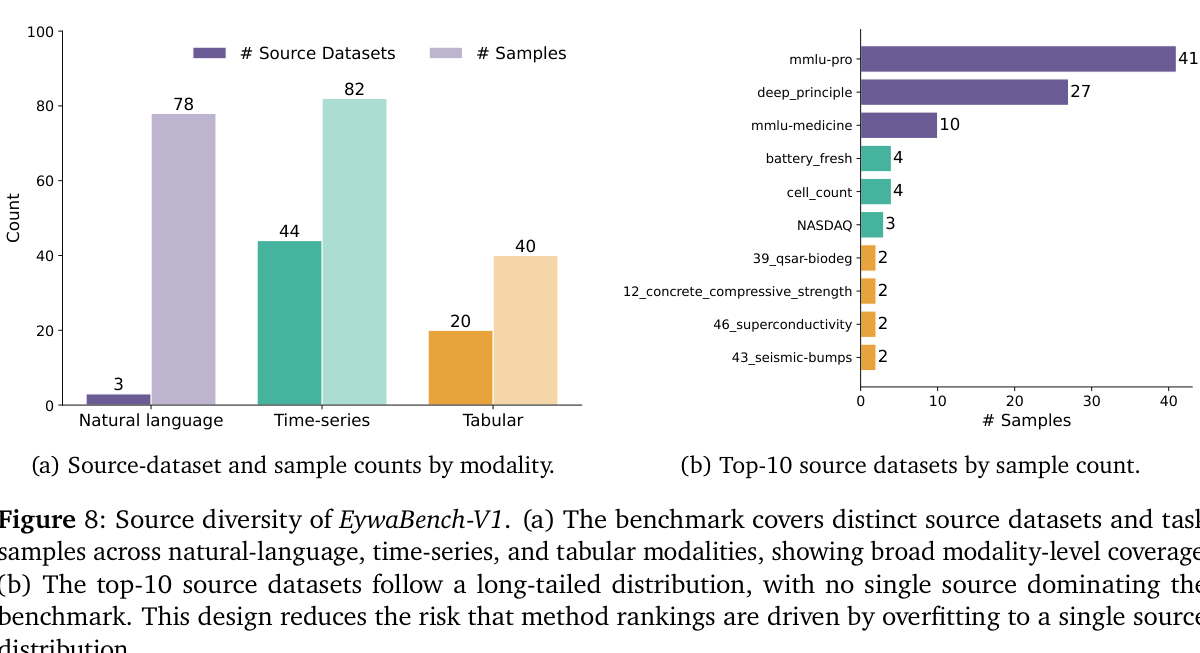
Figure 8. EywaBench mixes natural-language, time-series, and tabular sources with a long-tailed source distribution rather than one dominant dataset.

Figure 9. The benchmark is explicitly organized as parent domain → sub-domain → modality, which is exactly the kind of structure Eywa is meant to exploit.
Whole-System Performance
The table below reproduces the main EywaBench comparison, and the follow-up panels summarize what those numbers actually mean.
| Method | Metrics | Physical Science | Life Science | Social Science | Overall | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Material | Energy | Space | Biology | Clinic | Drug | Economy | Business | Infrastructure | |||
| Single-Agent Setting | |||||||||||
| Single-LLM-Agent | Utility (↑) | 0.5616 | 0.8202 | 0.5235 | 0.3402 | 0.4582 | 0.6004 | 0.7689 | 0.6528 | 0.6758 | 0.6154 |
| Time (↓) | 34.48 | 27.01 | 26.00 | 34.68 | 22.37 | 21.13 | 22.67 | 22.28 | 18.42 | 25.22 | |
| Tokens (↓) | 6367 | 4854 | 4512 | 6164 | 3618 | 3571 | 4097 | 3915 | 3327 | 4469 | |
| EywaAgent (Ours) | Utility (↑) | 0.5871 | 0.8390 | 0.6123 | 0.3718 | 0.5085 | 0.6199 | 0.8048 | 0.7371 | 0.7060 | 0.6558 |
| Time (↓) | 34.88 | 24.42 | 23.12 | 30.84 | 20.32 | 15.84 | 19.71 | 20.98 | 15.99 | 22.78 | |
| Tokens (↓) | 5040 | 3167 | 3329 | 4858 | 2333 | 2210 | 2791 | 2444 | 2248 | 3137 | |
| Multi-Agent Setting | |||||||||||
| Refine MAS [2023] | Utility (↑) | 0.5687 | 0.8667 | 0.6244 | 0.3623 | 0.4504 | 0.6215 | 0.7523 | 0.6880 | 0.6362 | 0.6294 |
| Time (↓) | 72.76 | 64.22 | 79.65 | 75.21 | 51.89 | 50.63 | 62.33 | 48.54 | 47.49 | 60.59 | |
| Tokens (↓) | 11013 | 9009 | 10043 | 10497 | 7029 | 7498 | 8924 | 6997 | 7438 | 8673 | |
| Debate MAS [2024] | Utility (↑) | 0.5602 | 0.8656 | 0.6543 | 0.3438 | 0.4738 | 0.6198 | 0.7729 | 0.6907 | 0.7237 | 0.6460 |
| Time (↓) | 82.06 | 79.46 | 74.75 | 101.64 | 78.19 | 63.98 | 92.72 | 72.46 | 60.73 | 78.22 | |
| Tokens (↓) | 16652 | 14278 | 13614 | 17007 | 11159 | 10447 | 14694 | 10953 | 10311 | 13216 | |
| MoA [2025] | Utility (↑) | 0.5909 | 0.8069 | 0.5863 | 0.3580 | 0.4722 | 0.5686 | 0.7499 | 0.7004 | 0.6938 | 0.6273 |
| Time (↓) | 90.15 | 56.95 | 69.32 | 59.10 | 46.53 | 44.31 | 57.35 | 48.29 | 47.34 | 57.75 | |
| Tokens (↓) | 25327 | 16453 | 17332 | 15980 | 11014 | 10344 | 16114 | 11690 | 12365 | 15317 | |
| X-MAS [2025] | Utility (↑) | 0.5831 | 0.8057 | 0.5723 | 0.3737 | 0.4490 | 0.6211 | 0.6923 | 0.6390 | 0.7180 | 0.6188 |
| Time (↓) | 104.48 | 86.63 | 79.06 | 88.20 | 67.94 | 59.76 | 75.50 | 72.82 | 62.95 | 77.42 | |
| Tokens (↓) | 24149 | 19808 | 16584 | 18451 | 12549 | 11907 | 16499 | 14007 | 14056 | 16537 | |
| EywaMAS (Ours) | Utility (↑) | 0.6381 | 0.8742 | 0.6899 | 0.3798 | 0.5086 | 0.6248 | 0.7959 | 0.7284 | 0.7406 | 0.6761 |
| Time (↓) | 77.25 | 75.96 | 72.51 | 111.92 | 59.97 | 59.23 | 68.40 | 58.11 | 46.49 | 72.11 | |
| Tokens (↓) | 14529 | 11709 | 11787 | 16502 | 9407 | 8078 | 11044 | 9470 | 8912 | 11214 | |
| Dynamic Orchestration | |||||||||||
| EywaOrchestra (Ours) | Utility (↑) | 0.6249 | 0.8711 | 0.7187 | 0.3682 | 0.5159 | 0.6319 | 0.7830 | 0.7388 | 0.7298 | 0.6746 |
| Time (↓) | 61.78 | 39.92 | 75.47 | 67.88 | 45.38 | 45.94 | 49.13 | 34.18 | 28.80 | 48.16 | |
| Tokens (↓) | 11535 | 7723 | 10810 | 11315 | 7050 | 6495 | 7117 | 7264 | 6892 | 8335 | |
Full EywaBench comparison across utility, time, and token usage. Best values are bolded, and second-best values are underlined to mirror the paper table.
EywaAgent improves both quality and efficiency
Under the same backbone, EywaAgent raises utility while cutting latency and reducing tokens by nearly 30% through specialist delegation.
EywaMAS beats homogeneous MAS baselines
EywaMAS achieves the best overall fixed-system utility and outperforms Refine and Debate in scientific settings.
LLM-only heterogeneity is not enough
Methods that only combine multiple language models do not consistently beat strong homogeneous MAS baselines on EywaBench.
Heavier MAS is not always necessary
On some domains such as economy and business, a single EywaAgent is already highly competitive, which motivates adaptive orchestration.
EywaOrchestra gets close at lower cost
The planner reaches utility close to expert-designed EywaMAS while lowering token and latency cost and removing expert configuration overhead.
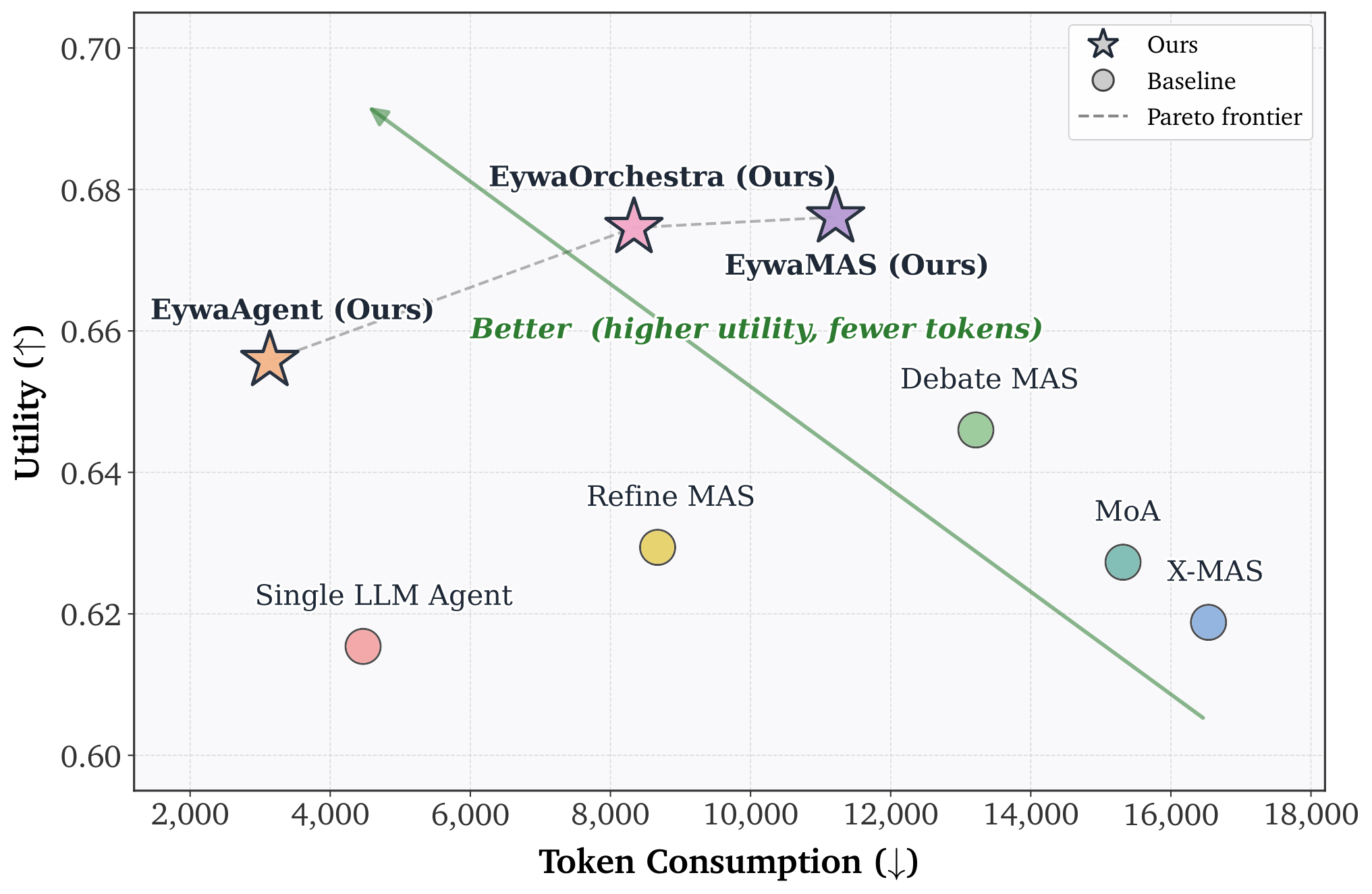
Figure 5. On the global utility-token plot, Eywa methods move the frontier upward and left: higher utility with fewer tokens than language-only baselines.
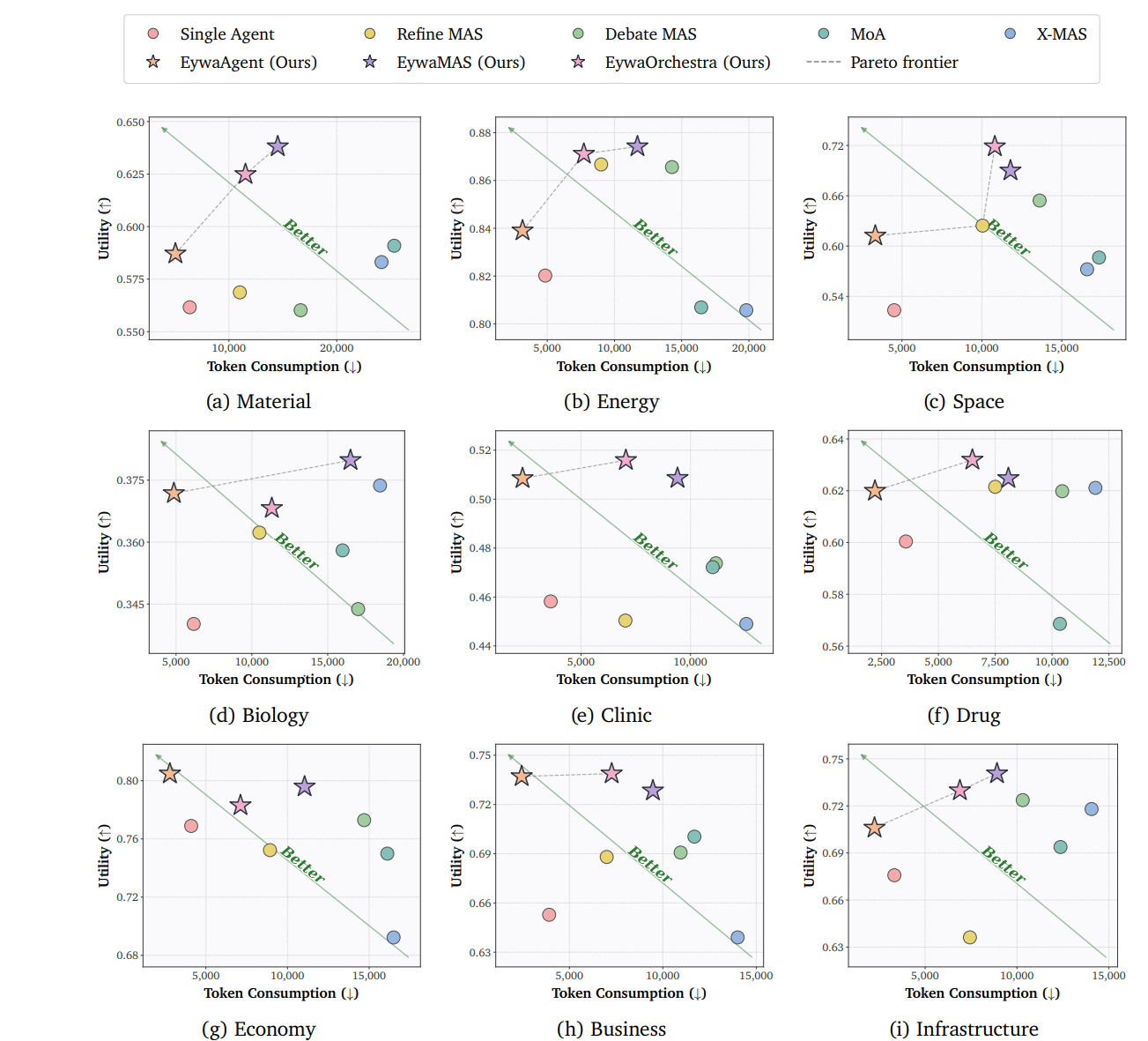
Figure 13. The same trade-off pattern largely persists when broken out across the nine scientific sub-domains.
Robustness and Backbone Effects
The paper's ablations show that Eywa's gains are not tied to one narrow prompt or hyperparameter setting.
Across sampling temperatures
Performance remains broadly steady as LLM temperature varies, suggesting the framework is not brittle to one decoding setting.
Across FM calibration
Changing the TabPFN softmax temperature does not erase the benefit of specialist delegation.
Prompts help a bit more
Detailed, chain-of-thought, and ReAct-style prompting all work, with more structured designs usually helping slightly.
BibTeX
@misc{li2026heterogeneous,
title = {Heterogeneous Scientific Foundation Model Collaboration},
author = {Zihao Li and Jiaru Zou and Feihao Fang and Xuying Ning and
Mengting Ai and Tianxin Wei and Sirui Chen and Xiyuan Yang and
Jingrui He},
year = {2026},
note = {Preprint},
url = {https://github.com/Violet24K/Eywa},
}